This is part of a series of tutorials I’m writing for CS231n: Convolutional Neural Networks for Visual Recognition. Go to this page to see the full listing.
To conserve space, I won’t be placing my full solutions in this post. Refer to my github repository for full source code.
The loss function is covered in the lecture and course notes. However, I find myself a little lost when looking for the formula for the gradient. What I find on the internet usually looks something like this:


And I have a lot of trouble figuring out how to implement it. Fortunately, there are notes on this, though not explicitly linked in the course site itself. Here is the link. I wasn’t able to see how these 2 formulas are also the derivative of the Softmax loss function, so anyone who is able to explain that I’d be really grateful.
For each sample, we introduce a variable p which is a vector of the normalized probabilities (normalize to prevent numerical instability. Refer to course notes: “Practical issues: Numeric stability.“):
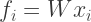

In my naive solution, this is implemented as a lambda function:
f_i = X[i].dot(W) f_i -= np.max(f_i) sum_j = np.sum(np.exp(f_i)) p = lambda k: np.exp(f_i[k]) / sum_j
The cross-entropy loss function L for a sample i is therefore:

Total loss for all m samples with regularization is then:
![L = \frac{1}{m}\sum_i \left[-\log\left(p_{y_i}\right)\right] + \frac{1}{2}\lambda \sum W^2](https://s0.wp.com/latex.php?latex=L+%3D+%5Cfrac%7B1%7D%7Bm%7D%5Csum_i+%5Cleft%5B-%5Clog%5Cleft%28p_%7By_i%7D%5Cright%29%5Cright%5D%C2%A0%2B%C2%A0%5Cfrac%7B1%7D%7B2%7D%5Clambda+%5Csum+W%5E2&bg=ffffff&fg=333333&s=2&c=20201002)
The gradient for a class k for a given sample i is therefore:

(Recall that 1 is the indicator function that is one if the condition inside is true or zero otherwise)
When converting to vectorized implementation, as with SVM, you need to somehow change to use a single dot product operation. Fortunately this is simpler than SVM. We define a matrix Q where the number of rows (each sample as i) is the sample size, and the columns (each class as k) being the number of classes:
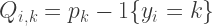

Here is a snippet of the implementation:
num_train = X.shape[0] f = X.dot(W) f -= np.max(f, axis=1, keepdims=True) # max of every sample sum_f = np.sum(np.exp(f), axis=1, keepdims=True) p = np.exp(f) / sum_f ind = np.zeros_like(p) ind[np.arange(num_train), y] = 1 Q = p - ind dW = X.T.dot(Q)
Though not in the python notebook, I added the loss plot function (with some slight alterations) from the SVM notebook to visualize the loss as the number of iterations increase. You can refer to my python notebook for the code; I will only show you the plot result, which looks remarkably similar to SVM:

You should be able to get a validation accuracy pretty close to 0.4 (I got about 0.39).
When visualizing the weights, you should get a somewhat similar result to the SVM classifier:


{kind=link}
“I wasn’t able to see how these 2 formulas are also the derivative of the Softmax loss function, so anyone who is able to explain that I’d be really grateful.”
I also spent quite some time to figure the derivative out. Here comes why.
Provided u = e^fi, v = Sigma(e^fj),
1. When i=j, d(u/v) = du/v + u*dv/(v^2)
2. When i!=j, d(u/v) = u*dv/(V^2)
LikeLiked by 1 person