The 1-0 knapsack problem; an optimization puzzle famously solved with dynamic programming (dp). This post is merely my take on the problem, which I hope to provide a more hands-on approach.
To get started, try and attempt The Knapsack Problem (KNAPSACK) from SPOJ. Study the problem closely as I will referring to it throughout this guide. I will then explain how the general solution is derived and how dp is applied.
I assume you have known a bit of dp as a prerequisite, though if you haven’t you can check out my beginner friendly hands-on intro: 445A – Boredom – CodeForces Tutorial.
The General Solution
A dp solution is usually derived from a recursive solution. So let’s start with that.
We define 2 containers: v and c, that contains the all the values of each item and the capacity they consume respectively, starting from index 1. So for example, v[2] and c[2] returns the value and size of the 2nd item.
What are we trying to optimize here? We are trying to maximize the value; the combination of items that yields the highest value. So let us define a function B(i, w) that returns the maximum value given a scope of items (i) and the capacity of the knapsack (w). The solution to KNAPSACK will therefore be B(N, S).
In solving it recursively, imagine we have all N items with us and our knapsack completely empty (current capacity is S), and we consider the items one by one from the last one (the N-th item).
What are the base cases of this problem? When there are no items to put in (i = 0), or when the knapsack cannot contain any items (w = 0).
Before we consider some i-th item, we first need to make sure that it can fit into the knapsack given its capacity, in other words, an i-th item should not be considered if c[i] > w. If this is so, you will consider the maximum value of the the scope of items excluding the i-th item, or B(i-1, w).
So what happens when you can put the item in the knapsack? You have 2 choices: To put it in (take), or not put it in (keep).
- Keep: you exclude it from the scope of items in which you consider the maximum value, which is again B(i-1, w).
- Take: you will get the value of the i-th item you select (v[i]), BUT, we should also consider the remaining space after adding the i-th item inside (w-c[i]). When considering items to add here, we need to exclude the item we already added, so the scope of items we consider is i-1. With this remaining space and this scope of items, we also want to get the maximum value. We can do this recursively via B(i-1, w-c[i]).
Choosing between keep and take is as simple as taking the maximum of the 2.
If you piece all this together, you will get the general solution:
![B(i,j) = \begin{cases} 0 \text{ if } i = 0\text{ or }w = 0\\ B(i-1, w) \text{ if } c[i] > w\\ max\Big( B(i-1, w), v[i] + B(i-1, w-c[i]) \Big) \end{cases}](https://s0.wp.com/latex.php?latex=B%28i%2Cj%29+%3D+%5Cbegin%7Bcases%7D+0+%5Ctext%7B+if+%7D+i+%3D+0%5Ctext%7B+or+%7Dw+%3D+0%5C%5C+B%28i-1%2C+w%29+%5Ctext%7B+if+%7D+c%5Bi%5D+%3E+w%5C%5C+max%5CBig%28+B%28i-1%2C+w%29%2C+v%5Bi%5D+%2B+B%28i-1%2C+w-c%5Bi%5D%29+%5CBig%29+%5Cend%7Bcases%7D&bg=ffffff&fg=333333&s=1&c=20201002)
Recursive Solution
Short and simple:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <iostream> | |
| #include <vector> | |
| #include <algorithm> | |
| using namespace std; | |
| vector<int> v, c; | |
| int B(int i, int w) | |
| { | |
| if (i == 0 || w == 0) return 0; | |
| if (c[i] > w) return B(i – 1, w); | |
| return max(B(i – 1, w), v[i] + B(i – 1, w – c[i])); | |
| } | |
| int main() | |
| { | |
| int S, N; cin >> S >> N; | |
| // sloted in for easy array access; values won't be used. | |
| c.push_back(-1); | |
| v.push_back(-1); | |
| int ct, vt; | |
| for (int i = 0; i < N; i++) { | |
| cin >> ct >> vt; | |
| c.push_back(ct); | |
| v.push_back(vt); | |
| } | |
| cout << B(N, S); | |
| } |
Plug it in the judge and you will get a TLE (Time Limit Exceeded).
Dynamic Programming Solution
We use a 2D array, DP, containing N+1 rows and S+1 columns. The rows map to the scope of i items we consider (the top considers 0 items and the bottom considers all N items). The columns map to capacity (an individual column is denoted as the w-th column) of knapsack left to right from 0 to S. A cell DP[i][w] means “this is the maximum value given i items and capacity of w“. The maximum value for N items and capacity of S is therefore DP[N][S].
We first fill DP with base cases: where i = 0 and where w = 0. This means that the first row and first column are all 0. The order in which we solve this is simple: starting where i = 1 and w = 1, for each row from top to bottom, we fill the cells from left to right.
I will continue on with an example using inputs from Tushar Roy’s YouTube video (you should check it out), but I jumbled the order to prove that ordering of items is not important. Here is the DP array:

Cells shaded in pale blue is when item does not fit in capacity w, or where c[i] > w. In pale green cells we have a choice: keep or take. Notice that with every row, we are adding one more item to consideration, and with every column we increase the capacity by 1.
Here is the code:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <iostream> | |
| #include <vector> | |
| #include <algorithm> | |
| using namespace std; | |
| int main() | |
| { | |
| vector<int> v, c; | |
| int S, N; cin >> S >> N; | |
| // sloted for easy array access; values won't be used. | |
| c.push_back(-1); | |
| v.push_back(-1); | |
| int ct, vt; | |
| for (int i = 0; i < N; i++) { | |
| cin >> ct >> vt; | |
| c.push_back(ct); | |
| v.push_back(vt); | |
| } | |
| vector< vector<int> > DP(N + 1, vector<int>(S + 1, 0)); | |
| for (int i = 1; i <= N; i++) { // i is scope of items in consideration | |
| for (int w = 1; w <= S; w++) { // j is max size of bag | |
| if (c[i] > w) { | |
| DP[i][w] = DP[i – 1][w]; | |
| } else { | |
| DP[i][w] = max(DP[i – 1][w], v[i] + DP[i – 1][w – c[i]]); | |
| } | |
| } | |
| } | |
| cout << DP[N][S]; | |
| } |
Getting the Selected Items
Some people use an auxiliary Boolean array (often called Keep) that keeps track of whether an item is selected or not. This seems to be an unnecessary occupation of space to me, since you can deduce the selected items from DP itself.
You start from DP[N][S], and from there:
- An item is selected, if the value of the cell directly above it is not equal to the current cell. When this happens, the capacity of the knapsack reduces by the weight of the selected item. With that new capacity you select the next item.
- An item is not selected, if the value of the cell directly above it is equal to the current cell. So we consider the next item by moving up one row; capacity remains unchanged.
This process continues until either there are no more items remaining, or the knapsack is full.
The table below shows the trail of the algorithm as it selects items (item 1 and 4) from the DP array we constructed before:

Below is the recursive function:
void pick(int i, int w)
{
if (i <= 0 || w <= 0) return;
int k = DP[i][w];
if (k != DP[i - 1][w]) {
cout << i << " "; // select!
pick(i - 1, w - c[i]); // capacity decreases
} else {
// move on to next item; capacity no change
pick(i - 1, w);
}
}
See the full implementation of this function in this gist.
Application
Enough spoon feeding! It is time for you to try out some puzzles on your own. Conveniently UVa grouped a series of 3 questions that are slight variations of the 1-0 knapsack problem. I sort them here in order of difficulty:
- 10130 – SuperSale (my solution)
- 990 – Diving for Gold (my solution)
– You will need to list down the items you select in this one.
– Beware of the tricky formatting! There shouldn’t be a blank line at the end of your output. - 562 – Dividing coins (my solution)
– In my solution, there is a tip (short comment block before the main function) you can check out if you just want some pointers to get started.
References
- Dynamic Programming | Set 10 ( 0-1 Knapsack Problem) (www.geeksforgeeks.org/)
- Dynamic-Programming Solution to the 0-1 Knapsack Problem (www.personal.kent.edu)

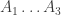 multiplies with a suffix from a chain
multiplies with a suffix from a chain 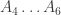 .
.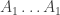 and a suffix
and a suffix  . In this prefix
. In this prefix 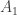 . The suffix
. The suffix 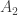 and
and 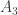 .
.
![mult(i, j)=\begin{cases}A_i \text{ if } i = j\\mult(i, k) \cdot mult(k+1, j)\text{ where } k = splits[i][j]\end{cases}](https://s0.wp.com/latex.php?latex=mult%28i%2C+j%29%3D%5Cbegin%7Bcases%7DA_i+%5Ctext%7B+if+%7D+i+%3D+j%5C%5Cmult%28i%2C+k%29+%5Ccdot+mult%28k%2B1%2C+j%29%5Ctext%7B+where+%7D+k+%3D+splits%5Bi%5D%5Bj%5D%5Cend%7Bcases%7D&bg=ffffff&fg=333333&s=0&c=20201002)
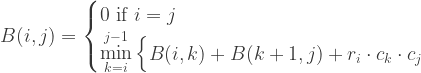
 ), and then the more optimal dynamic programming solution (
), and then the more optimal dynamic programming solution (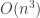 ).
).
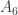 , followed by the column of matrix
, followed by the column of matrix  ). So for brevity sake we do not need to put rows and columns of all matrices (otherwise the sequence will look like 30 35 35 15 15 5 5 10 10 20 20 25).
). So for brevity sake we do not need to put rows and columns of all matrices (otherwise the sequence will look like 30 35 35 15 15 5 5 10 10 20 20 25). is rc[i] and the column is rc[i+1].
is rc[i] and the column is rc[i+1].



 or
or 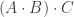 ) the chain it will give you the same answer, thus we say it is
) the chain it will give you the same answer, thus we say it is 
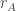 and the column as
and the column as 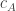 , then the total number of multiplications required to multiply A and B is
, then the total number of multiplications required to multiply A and B is 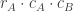 .
. we wish to parenthesize the product of this sequence so as to minimize the number of operations required.
we wish to parenthesize the product of this sequence so as to minimize the number of operations required.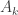 , and a suffix can only start from
, and a suffix can only start from  to
to  , split at some index k. The cost in the last operation for the prefix is then B(1, k) and the cost of the suffix is B(k+1, n). k therefore ranges from 1 until n-1 in the last operation, and within a range i to j, k ranges from i to j-1. We choose k by selecting the minimum cost of all the possible costs within a range i to j.
, split at some index k. The cost in the last operation for the prefix is then B(1, k) and the cost of the suffix is B(k+1, n). k therefore ranges from 1 until n-1 in the last operation, and within a range i to j, k ranges from i to j-1. We choose k by selecting the minimum cost of all the possible costs within a range i to j. If we split at a point k, the resultant dimensions of the prefix is
If we split at a point k, the resultant dimensions of the prefix is 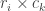 and the suffix is
and the suffix is  . The cost of multiplying these 2 matrices are therefore
. The cost of multiplying these 2 matrices are therefore 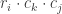 .
.
 and
and  . How we choose between the 2 is determined by cost of either multiplying
. How we choose between the 2 is determined by cost of either multiplying 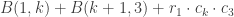 , and we choose between
, and we choose between  and
and  . You can continue doing this for 4 or 5 or 6 matrices until you start to see a pattern. Notice you can apply the same procedure to find B(1, 3) to find B(1, 2) – there is only 1 possible value for k for B(1, 2).
. You can continue doing this for 4 or 5 or 6 matrices until you start to see a pattern. Notice you can apply the same procedure to find B(1, 3) to find B(1, 2) – there is only 1 possible value for k for B(1, 2).