This is a 3 part series of Deep Q-Learning, which is written such that undergrads with highschool maths should be able to understand and hit the ground running on their deep learning projects. This series is really just the literature review section of my final year report (which in on Deep Q-Learning) broken to 3 chunks:
- Part 1 – Convolutional Neural Networks
- Part 2 – Reinforcement Learning
- Part 3 – Deep Q-Learning
Prologue: A Brief History
In as early as 1954, scientists began to speculate that psychological principles in learning will become important to building artificial intelligent systems (Minsky, 1954). The science and study of teaching computers to learn from experience become eventually known as reinforcement learning (RL).
Successful implementations of RL algorithms began in 1959 when Arthur Samuel published his work on an AI that can master checkers simply by playing with itself (Samuel, 1959). In this seminal work, he pioneered various ideas on RL, one of which spawn to a class of learning techniques known as temporal difference (TD) learning. Later in 1992, Gerry Tesauro had similar success in the game backgammon with his program, TD-Gammon (Tesauro, 1995), which surpassed all previous computer programs in its ability to play backgammon. What is new in Tesauro’s work is that TD-Gammon combines TD learning with another AI technique that is inspired by biological brains: a neural network.
However, in spite of these advances, in both Samuel’s checker program and TD-Gammon, the input is distilled to what the computer can understand (board positions), and the rules are hard-coded to the machine. This no longer becomes the case when DeepMind publishes a novel technique known as Deep Q-Learning. It made its official debut by playing retro console games off an Atari 2600 emulator (Mnih et al., 2013), and in certain games the AI is even able to outmatch expert human players. What is significant about Deep Q-Learning is that the AI learns by seeing the same output on the game console as human players do, and figures out the rules of the game without supervision. As with TD-Gammon, Deep Q-Learning also used an artificial neural network, albeit a different architecture – convolutional neural network (CNN).
Introduction
In all the hype about machine learning in this era, some people call reinforcement learning (RL) a hybrid between supervised and unsupervised learning. Some people place reinforcement learning in a different field altogether, because knowing supervised and unsupervised learning does not mean one would understand reinforcement learning, and vice versa.
The core idea of RL comes natural to us even as an infant. We are born in a world which we knew very little of, in a body which we do not choose, and with little supervision. We learn remedial tasks, such as walking and talking, by continuously trying until we get it right. An infant does not have an understanding of failure and success; he makes attempts, sees that some things work, and some don’t, and focus more of what works. He does not get depressed or frustrated even if he keeps falling when he tries to walk. Really the only people getting emotional of his attempts are his parents. As we get older we derive more unnecessarily complex views of the concept of what should work and what is success, but that is besides the point here.
RL is the study of a computational approach to learning by trying. We teach a computer to learn as we do: by repeatedly interacting with the environment, and learning from prior experience. For example, a robot learns to find a path out of a maze by trying out different routes that it can see. To put it in more formal terms, we have an agent (robot) that starts in an initial state (robot’s position and what it sees), take an action (movement in some direction) in an environment (the maze), which would then return a reward (some score to let the robot know how close it is to finishing the maze) and a new state.

The agent-environment interaction in RL. (Sutton & Barto, 1998)
Should we describe supervised learning in terms of this agent-environment interface, we could say that an action (input) comes together with the reward (target); we train a model with both the input and the expected answer. RL introduces the concept of delayed rewards, where the agent is only aware of the reward after the action is taken. This meant that during training, the agent attempts an action, but will not know if it is the best course of action (determined by a reward value) until after it has taken an action and after it has landed on a new state.
Markov Decision Process
Markov Decision Process (MDP) introduces a mathematical framework for describing decision making in a probabilistic environment. All RL algorithms in this series will be described using MDP.
Time in the real world is continuous; but in MDP, time is discrete, described in time steps in fixed intervals: 

- A set of states
, where
is the set of all possible states.
- A set of all actions
, where
is the set of all possible actions that can be taken in the state
.
- A transition function
which returns the probability that if at time
in the state
we would end up in new state
in a next time step
.
- A reward function
, which is the consequence of the action and comes 1 time step later. This value is normally an integer, and can also be negative value (punishment).
Transition and reward functions are also written as 
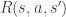
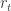
In MDP, possible actions in a current state depends only on the current state. What happens in the past and what will happen in the future does not affect what actions an agent can take now.
MDPs are used to model non-deterministic (or stochastic) search problems. This is different from deterministic search because unlike deterministic problems, non-deterministic problems do not have a fixed sequence of actions from start to finish as a final answer. The fundamental problem of an MDP is to find a policy 
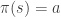



Utility
We now know that the goal of the agent is to decide on what actions to maximize the sum of rewards. But to decide on an action the agent needs to have an expectation of what reward it will get. This expected reward is known as the utility (or value). There are 2 ways we can compute a value (Marsland, 2015):
- State-value function,
– We consider the current state, and average across all of the actions that can be taken.
- Action-value function,
– We consider the current state and each possible action that can be taken separately. This is also known as a Q-value. A Q-state
is when you were in a state and took an action.
In either case we are thinking about what the expected reward would be if we started in state s (where 

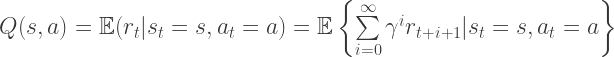
The utility starting in a state 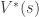





V∗ and Q∗ values in grid world example (Klein, 2014)
This is illustrated in the grid world example in figure above. Here the agent navigates from one box (each box represents a state) to another until it reaches a terminal state: a box with double outlines. In each state the agent chooses between 4 different directions, each of which is a possible action. Notice that the highest utility in each Q-state box is the utility of a V-state box.
The Bellman Equations
How shall we characterize optimal utilities? We will use bellman equations. The intuition behind it is to take the correct first action, and from then onwards continue to be optimal. This is done in a recursive fashion:
![Q^*(s, a) = \sum_{s'} T(s, a, s') \left[ R(s, a, s') + \gamma V^*(s') \right]](https://s0.wp.com/latex.php?latex=Q%5E%2A%28s%2C+a%29+%3D+%5Csum_%7Bs%27%7D+T%28s%2C+a%2C+s%27%29+%5Cleft%5B+R%28s%2C+a%2C+s%27%29+%2B+%5Cgamma+V%5E%2A%28s%27%29+%5Cright%5D&bg=ffffff&fg=333333&s=2&c=20201002)
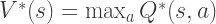
![V^*(s) = \max_a \sum_{s'} T(s, a, s') \left[ R(s, a, s') + \gamma V^*(s') \right]](https://s0.wp.com/latex.php?latex=V%5E%2A%28s%29+%3D+%5Cmax_a+%5Csum_%7Bs%27%7D+T%28s%2C+a%2C+s%27%29+%5Cleft%5B+R%28s%2C+a%2C+s%27%29+%2B+%5Cgamma+V%5E%2A%28s%27%29+%5Cright%5D&bg=ffffff&fg=333333&s=2&c=20201002)
In these equations, we find all possible consequent states that can result from from taking action 

Value Iteration Algorithm
Now that we know what 
We assume there will always exist an optimal Q-value for each Q-state. At first, all Q-states will be initialized to small random values. Then we will iterate through every possible state, evaluating its future states in the process. With a proper discount rate
The value iteration algorithm for finding

Notice that in the value iteration algorithm, the probability of entering a state
Q-Learning
Q-Learning (Watkins, 1989) belongs to a class of RL methods called temporal difference learning. It offers an online algorithm to iteratively approximate Q-values without knowing the transitions between states.
This is done with an update function that finds the temporal difference between learning experiences. Temporal difference simply means the difference between the reward at this current step and the estimated reward we got at the previous step. The Q-values are then determined by a running average. Naturally, the more we iterate, the closer we converge to optimal
To do this we break down how we find our Q-values: instead of recursively computing an infinite amount of time steps, we use a one-step value iteration update given by the Bellman equation, which is just depth-one expansion of the recursive definition of a Q-value:
This will be our estimated utility for the current state. Let us call this estimated utility 


The Q-Learning algorithm is given in Algorithm 3:
In the update function, 

![Q(s, a) \gets Q(s, a) + \alpha \left[y - Q(s, a)\right]](https://s0.wp.com/latex.php?latex=Q%28s%2C+a%29+%5Cgets+Q%28s%2C+a%29+%2B+%5Calpha+%5Cleft%5By+-+Q%28s%2C+a%29%5Cright%5D&bg=ffffff&fg=333333&s=2&c=20201002)

As time passes, it is usually the case that we incrementally reduce
Note that in Q-learning we do not use the policy to find the value of 
Afterword
If you want to learn more about RL, I would recommend looking up the AI course (CS188) from the university of Berkeley. I didn’t actually finish the course – just the lectures that involve RL, and attempted the corresponding programming assignments. The grid world example is taken from there; it is actually a programming assignment (python3) where you have to write the code to compute the Q values. Marsland’s Machine Learning textbook only takes up a small part to talk about RL, but the material is relatively easier to understand, not to mention that it comes with python source code. The definitive guide to RL would definitely be Sutton’s RL book, but I had a lot of difficulty understanding it, since it just teach concepts.
I understand if the material here is pretty esoteric; I took a long time to understand it myself. However, if you manage to make it thus far, you are ready to understand the Deep Q-Learning algorithm, which I will cover in the final part of this series.
References
- Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning: An introduction (Vol. 1) (No. 1). MIT press Cambridge.
- Minsky, M. L. (1954). Theory of neural-analog reinforcement systems and its application to the brain model problem. Princeton University.
- Samuel, A. L. (1959). Some studies in machine learning using the game of checkers. IBM Journal of research and development, 3(3), 210–229.
- Tesauro, G. (1995). Temporal difference learning and td-gammon. Communications of the ACM , 38(3), 58–68.
- Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
- Marsland, S. (2015). Machine learning: an algorithmic perspective. CRC press.
- Klein, D. (2014). Cs 188: Artificial intelligence. University of California, Berkeley.
- Watkins, C. J. C. H. (1989). Learning from delayed rewards (Unpublished doctoral dissertation). University of Cambridge England.
