I have spent a lot more time than I should be looking into solutions on database migrations for RDBMS. Sure, on the surface, there may seem only a few ways to hammer a nail, but dig a little more and it is an endless rabbit hole. I figured in this writeup I will put together all the various techniques and ideas on handling database migrations.
These ideas are mainly assembled from 7 different database migration systems 🥊:
- Flyway 🕊 – SQL file-based database migration system
- Liquibase 💧 – flexible migration system with a monitoring dashboard
- Django 🐍 – Web framework for Python
- Active Record 🚂 – ORM for Ruby on Rails
- Entity Framework 🌏 – ORM for .NET
- Alembic ⚗️ – database migration tool for SQLAlchemy (Python).
- Skeema 📏 – pure-SQL schema management utility.
Now, just because I didn’t mention them here doesn’t mean they are not good. There are simply too many, and I’ve only looked into these 7 in detail. You are welcome to comment your favourite below and how it stacks up against the competition.
Introduction: The Evolving Database Problem
In production systems, there is typically no such thing as a final database schema. Similar to your app releases, this “final” database is a moving target, and we only develop with the most recent database version (or state). New tables, columns are added, dropped, renamed over time; data gets shuffled to different places – a database tends to evolve from one version to another. It gets messy real quick with a team of developers, so a database migration system eventually gets introduced, and it is not uncommon that companies will opt to build theirs in-house.
There is a great article by Martin Fowler introducing evolutionary database design, as well as techniques and best practices.
Essential Components
Although database migration systems may have a plethora of ideas of how to go solve the evolving database problem, practically all of them shares 4 essential components:
- Migration/revision/changeset
- Rollback
- Repeatable migration
- Version tracking
Migration
A migration (flyway) or revision (alembic) or changeset (liquibase) is a single unit of change that brings a database from one version to another. One key problem database migration systems need to address during a migration run is execution order. I will go through 4 strategies on how to solve this:
- Filename
- Appearance order
- Relative revision
- Topological order
Filename. This is the simplest and most intuitive strategy. Chances are if you implement a migration system yourself this would be the first approach you would consider. In flyway, you would organise your migrations as such ('V' here stands for versioned migrations):
📂 migrations/
├──📄 V1__create_table_foo.sql
├──📄 V1.1__add_column_bar.sql
└──📄 V2__create_audit_tables.sqlWhen you execute flyway migrate, the files will be executed in numeric order. Note that by default, flyway does not execute migrations that are slipped in between executed migrations (e.g. if V1 and V2 have already been executed and you add V1.1 later, V1.1 does not get executed). This can be changed via the -outOfOrder parameter.
One problem with this approach is nothing stopping multiple developers from submitting the same version more than once; flyway will not accept ambiguity in versioning. A common solution for this is to have a CI run flyway migrate in pull requests. Combine this with only merging pull requests that are up to date with master, and you prevent these conflicts from entering your source code in the first place.
A simpler solution to solve duplicate versioning is using a timestamp. This is the most hassle-free way to resolve this and is the approach that Rails Active Record and .NET Entity Framework uses. After all, what are the odds of multiple developers creating a migration at precisely the same second right?? 😉
Here’s an example of Active Record migration folder:
📂 sample_rails_app/db/migrate/
├──📄 20190822013911_create_users.rb
├──📄 20190822021835_add_index_to_users_email.rb
└──📄 20190827030205_create_relationships.rbNote that you could also do this in flyway (e.g. V20210617115301__create_table_foo.sql) – but unlike flyway, both the migration filename and contents in Active Record and Entity are generated, where the prefix is the timestamp of migration creation. I will elaborate more on this later.
Appearance Order. A migration in liquibase is referred to as a changeset. Multiple changesets are stored in changelog file. When you first configure Liquibase you need to specify a single master changelog file. In addition to changesets, a changelog file can reference multiple changelog files. Liquibase then executes all changesets and referenced changelogs in order of appearance within the master changelog file, from top to bottom. This makes changing execution order trivial as compared to changing around filenames.
Liquibase recommends the following directory structure, where the changelog is named after the app release version (not the migration version):
📂 com/example/db/changelog/
├──📄 db.changelog-master.xml
├──📄 db.changelog-1.0.xml
├──📄 db.changelog-1.1.xml
└──📄 db.changelog-2.0.xmlThe order of execution is then dictated by the master file db.changelog-master.xml:
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<include file="com/example/db/changelog/db.changelog-1.0.xml"/>
<include file="com/example/db/changelog/db.changelog-1.1.xml"/>
<include file="com/example/db/changelog/db.changelog-2.0.xml"/>
</databaseChangeLog>
You can check out how this is used in practice in keycloak’s github repo (the master file is called jpa-changelog-master.xml, which is referenced here).
Note: It’s a pervasive misunderstanding that liquibase only supports XML. Hardcore DBAs can rejoice to know that you can also write your changesets in SQL. Doing so would deprive you of magical features, but liquibase does allow you to use both file types in the same project!
As with using filenames, conflicts do exist when multiple developers write to the same file, but liquibase claims that this is much simpler to deal with using version control systems like git.
Relative Revision. This is used in Alembic, where migrations are called revisions. The idea is that execution order is not dictated by appearance or filename, but relative from one revision to another, beginning from the initial revision. This can be confusing at first, for example when you see the migration folder in Apache Airflow it looks like this unordered mess:
📂 airflow/airflow/migrations/versions/
├──📄 004c1210f153_increase_queue_name_size_limit.py
├──📄 03afc6b6f902_increase_length_of_fab_ab_view_menu_.py
├──📄 ...
├──📄 f2ca10b85618_add_dag_stats_table.py
└──📄 fe461863935f_increase_length_for_connection_password.pyThe first 12 characters prefixed to every migration file is its hash, this is called a “revision ID” – it identifies a migration, but tells nothing about the execution order. To query the past execution order, you need to run alembic history.
Alembic determines ordering from 2 attributes in every revision file. Consider an initial revision 1975ea83b712_create_account_table.py that is generated by the alembic generate command:
# 1975ea83b712_create_account_table.py
revision = '1975ea83b712'
down_revision = None
The revision attribute is the same as the migration’s revision ID. Where down_revision is None, we know that this is a root node; the first revision that gets executed. Say another revision ae1027a6acf_add_some_column.py gets added (also generated by alembic generate):
# ae1027a6acf_add_some_column.py
revision = 'ae1027a6acf'
down_revision = '1975ea83b712'
This declares that revision ae1027a6acf revises 1975ea83b712, and therefore requires 1975ea83b712 to be executed first. So each subsequent revision from the root knows which revision it modifies, and from there you can build an execution order 1975ea83b712 → ae1027a6acf.
To run migrations, we use alembic upgrade head, where head will point to the most recent revision.
Though we would be tempted to think of this as a linked list, where each node has a reference to another node, in cases where there are multiple developers it is more like a tree. This is because Alembic allows multiple revisions to “branch” from a shared parent (i.e. there is more than one revision file that has the same down_revision). In such cases, alembic upgrade head will fail as there are multiple head‘s. To resolve this, a developer would use alembic merge to merge all heads into one. The Alembic branch docs have a nice ASCII art to illustrate this:

The merge command will create another revision file that fuses more than one revision to a single timeline. This is simply a revision file with multiple down_revision:
revision = '53fffde5ad5'
down_revision = ('ae1027a6acf', '27c6a30d7c24')
As you might be able to tell, these concepts on branching, merging, and head revision is very similar to git. And similar to git, you don’t have to create a merge commit; another strategy is “rebase”, which means you change the parent revision (i.e. down_revision). Assuming there are no conflicts, you can do away with the merge revision and get a clean timeline with no branches.
In the case of our above example, we would change the down_revision of 27c6a30d7c24 from 1975ea83b712 to ae1027a6acf (notice that we also removed 53fffde5ad5):

Topological order. This idea is unique in that it does not see migrations as a linear path with a start and end, but a directed acyclic graph (DAG) where the nodes are migrations and the edges are dependencies. An example of a dependency would be if you have a foreign key constraint, the table it points to must first exist. Now you can run migrations in any order you like, as long as dependencies are met; the execution order is thus defined by its topological order, and there can be many viable paths.
In Django, every model has its own migration folder. Take this example from Thinkster‘s Django Realworld Example App (simplified for brevity):
📂 django-realworld-example-app/conduit/apps
├──📂 articles
│ └──📂 migrations
│ ├──📄 0001_initial.py
│ ├──📄 0002_comment.py
│ └──📄 0003_auto_20160828_1656.py
└──📂 profiles
└──📂 migrations
├──📄 0001_initial.py
├──📄 0002_profile_follows.py
└──📄 0003_profile_favorites.pyEvery migration file has a dependencies attribute, which may contain zero or more dependencies. If a migration has no dependencies, it can be executed prior to other migrations. For example in 0003_profile_favorites.py:
dependencies = [
('articles', '0002_comment'),
('profiles', '0002_profile_follows'),
]
To make the concept more visually apparent, here is its DAG along with a viable topological order (from 1 to 6):
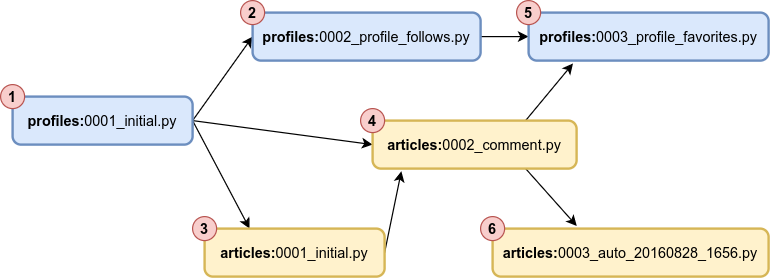
Read Django’s official documentation on this in “Controlling the order of migrations“
As pointed out earlier, there can be multiple viable execution orders for as long as the dependency conditions are satisfied. For the above example, the following is also a valid execution order:
- profiles:0001_initial.py
- articles:0001_initial.py
- articles:0002_comment.py
- profiles:0002_profile_follows.py
- articles:0003_auto_20160828_1656.py
- profiles:0003_profile_favorites.py
This seems complex, but it provides a lot of flexibility for developers, and greatly reduce the chance of conflicts. Also, developers working with Django are usually insulated from migration implementation details as it is generated via django-admin makemigrations command.
Rollback
A rollback reverts a specific migration. A simple case is when you add a column in a migration, its corresponding rollback would be to drop the column. Typically rollbacks are added within the same migration file, where a migrate function has a corresponding rollback function, as is the case for Entity Framework (Up and Down), and Alembic (upgrade and downgrade).
Some implementations (e.g. Django, Active Record) decide to go a step further by not even requiring an explicit rollback function; the migration tool automagically figures it out for you 🪄! In Liquibase, if you use their XML/YAML/JSON syntax, it can also automatically figure out how to rollback a changeset.
In flyway, rollbacks are called undo migrations; these are just SQL files that map to a corresponding migration (e.g. a V23__add_column_bar.sql is reverted by U23__drop_column_bar.sql). In addition, undo migrations are a paid feature in flyway; not only do you have to write them out by hand, but you also had to pay for a license to do it.
This is not all bad, since you may not always be able to generate or write a rollback. For example, although you can reverse adding a column, you can’t undrop a table or a column, and you can’t undelete rows; once data is gone, it is gone for real. In practice, DBAs tend to only go forward. If you regret some design decision in the past and want to revert it, you write another migration. However, rollbacks are still handy as a plan B in situations where deployments go horribly wrong despite meticulous planning.
Repeatable Migration
There are special cases where you would want to run a migration more than once. These are often stored procedures, and views – and in cases where business logic is part of the database, they are often changed.
Typically repeatable migration work by comparing the checksum of migration of past execution and current execution. Flyway prefixes repeatable migrations with R__, and they are always executed last in any migrate run. Liquibase supports a runOnChange changeset attribute that reruns the changeset when changes are detected.
ORM focused migration tools like Active Record, Entity Framework, Alembic, Django would presume you will never need repeatable migrations. In fact, if you come from ORM land, stored procedures and views are a foreign concept, if not frowned upon (as the rails purists would say, “It is not the rails way!” 🔥).
Although Alembic does not support repeatable migrations out of the box, there is a community contribution Alembic Utils that adds support for it… for Postgres only. Otherwise, you are left with implementing it yourself via this ReplaceableObject recipe in the Alembic cookbook.
Version Tracking
Version tracking is a technique to guarantee that migrations only execute once, or in the case of repeatable migrations – only when the migration has been modified.
Practically every database migration system will implement this as a tracking table in your database. Storing tracking information in your database guarantees atomicity during a migration run (i.e. if a migration fails the version is never tracked). Migration systems may also place a table-level write-lock on a migration table to assert such that only one migration run can happen at any given moment; this is particularly useful when you have multiple copies of your app connecting to the same database in parallel.
Version tracking tables go by many names: alembic_version (Alembic), __eFMigrationsHistory (Entity Framework), schema_migrations (Active Record), flyway_schema_history (Flyway), DATABASECHANGELOG + DATABASECHANGELOGLOCK (Liquibase), and django_migrations (Django).
Typically, tracking tables store only the migration version, identifier, or filename. Execution timestamp may also be stored, allowing developers to roll back to a specific point in time. In some implementations like Flyway and Liquibase, tracking tables also store checksums. These are used for 2 things:
- For normal migrations, checksum asserts that an executed migration has not been tampered with.
- For repeatable migrations, checksums are used to determine if migration needs to be re-executed.
Workflows
Although database migration systems share a lot of essential components, their workflows tend to differentiate them from the rest.
- Revision based workflow
- Code first workflow
For each workflow, there are 2 paradigms: either you write SQL that the database directly runs, or rely on source-code generation. In source-code generation, you write your migration in some other language than SQL (XML, C#, Ruby DSL,.. etc) that generates SQL code. It’s an extra step – yes, but developers love this approach with religious vigour. There are a few key reasons:
- It can support different database vendors
- Can do automatic rollbacks
- Allows developers to write in their favourite programming language
Alright, let us walk through the different workflows.
Revision Based Workflow
In a revision based workflow, you write your migration script first, and that determines the next database state. Then continue to add subsequent migration scripts continue to evolve the database over time.
In Flyway, you write raw SQL files the follows a specific naming convention. In Liquibase, you typically use XML, and that enables vendor-independent migrations as well as automatic rollbacks. Active Record takes this a step further with a command that generates migrations for you; use rails generate model command to create a migration file. For example:
rails generate model Post title:string link:string upvotes:integerThis creates db/migrate/20210627134448_create_posts.rb, written in Ruby DSL (Domain Specific Language):
class CreatePosts < ActiveRecord::Migration[5.2]
def change
create_table :posts do |t|
t.string :title
t.string :link
t.integer :upvotes
t.timestamps
end
end
end
To make changes to a model you use rails generate migration. For example to add a downvotes column to the posts table do:
rails generate migration AddDownvotesToPost downvotes:intMore than just being descriptive, the migration name you provide in the generate migration command is used to create the migration itself (i.e. it figures out you want to add a column to the posts table from the name AddDownvotesToPost).
Code First Workflow
A code first workflow can also be thought of as a declarative workflow: you first model out how you want your database to be, and let the migration system generate a migration.
Take this Entity Framework model (C#) from their getting started guide:
namespace ContosoUniversity.Models
{
public class Student
{
public int ID { get; set; }
public string LastName { get; set; }
public string FirstMidName { get; set; }
public DateTime EnrollmentDate { get; set; }
public virtual ICollection<Enrollment> Enrollments { get; set; }
}
}
Then you execute add-migration <DescriptionMigrationName> and a migration file (also in C#) is automagically generated. When you make changes to your classes, simply run add-migration to create a new migration file. In short, your C# classes determine the current state of your database. In Entity Framework lingo, this is known as “Code First Migrations“, and when I first saw this as a young developer 4 years ago, it blew my mind.
As I eluded to earlier, Django also generates its migration files from its models with its makemigrations command. Alembic supports this as well via an additional --autogenerate flag to the alembic revision command.
For folks that disdain source-code generation, Skeema allows you to declare the final schema in SQL, and it generates a SQL diff that changes the target database state to the declared state. In fact, it is so confident in this approach it does not even do version tracking. There are no replaying historical migration files; whether it be a new development instance or production database, we are always one migration away from the declared schema.
Even though it uses plain SQL, Skeema does not parse SQL code itself; it runs the SQL code in a temporary location called a workspace and compares it with the schema of your target database. The generated SQL can be reviewed via skeema diff, and deployed via skeema push.
Some caveats: as cool as code first workflows may sound, they would not cater to ambiguous cases. For example, did you rename column color to colour, or did you drop column color and added a new column colour? The simple answer is that there is no way to tell apart renames. Skeema details this drawback in its product announcement, but assures that renames rarely happen 😉.
Closing Thoughts
Finding the right approach is more than just performance or features. You need to think about developers in your team whether they want to work with some custom migration solution you found in a comment in Hackernews, that points to some GitHub repository with barely any activity or stars. Rarely would developers want to learn something just for one project. Any database migration system you introduce puts a learning curve for your team. Most likely those developers would know little SQL and would hardly have any interest in being good at it. Typically the database migration system they would opt to use is simply the one that comes bundled to the chosen web framework.
Database migration is a messy conundrum without perfect solutions. As I would come to learn – we simply need to decide what is best on a case by case basis.
